Perforce is source control software used in games, entertainment, and a few engineering sectors. It's particularly useful when large binary assets need to be stored alongside source code. It handles binary assets much better than Git, IMO. However, its one weakness is its terrible security defaults. You will die a bit inside when you see the out-of-the-box behaviour: "Don't have an account? Let me make one for you!" and "Oh, you didn't know by default there is a hidden, read-only 'remote' user that allows read access to everything? Oops!"
I scanned 6,122 public Perforce servers last year. 72% were exposing source code, 21% had passwordless accounts, and 4% had unprotected superusers (which allow RCE). The vendor patched the largest issue, but a significant portion are still vulnerable.
Hardening is a pain, but here it is summed up: p4 configure set security=4 # disables the built-in 'remote' user + strong auth p4 configure set dm.user.noautocreate=2 # kills auto-signup p4 configure set dm.user.setinitialpasswd=0 # users cannot self-set first password p4 configure set dm.user.resetpassword=1 # force password reset flow p4 configure set dm.info.hide=1 # hide server license, internal IP, root path p4 configure set run.users.authorize=1 # user listing requires auth p4 configure set dm.user.hideinvalid=1 # no hints on bad login p4 configure set dm.keys.hide=2 # hide stored key/value pairs from non-admins p4 configure set server.rolechecks=1 # prevent P4AUTH misuse
Years before the figure skater became an Olympic superstar, a Chinese operative tried to stalk her father and monitored other US residents deemed dissidents against China. And that’s just the beginning.
Most writeups of BlueHammer describe what it does. I read the actual PoC (FunnyApp.cpp, ~100KB of C++) and the most important line isn't in the oplock setup, the NT object namespace redirect, or the Cloud Files freeze. It's a comment.
The filestoleak array ships with one target active and two commented out:
SAM alone is a partial dump. The hashes are encrypted with the boot key — which lives in SYSTEM. Without SYSTEM you have ciphertext. With SAM + SYSTEM you have NTLM hashes you can pass-the-hash or crack offline. SECURITY adds LSA secrets: service account credentials, cached domain logon hashes, DPAPI master keys.
The complete credential package is two uncommented lines away from the published PoC. The author wrote both lines and chose what to ship.
Full analysis walks the actual code: the batch oplock on RstrtMgr.dll (not the EICAR file — that's what most writeups get wrong), the NtCreateSymbolicLinkObject swap in the session object namespace (not NTFS symlinks — a different layer entirely), the Cloud Files freeze via a fake OneDrive sync provider named IHATEMICROSOFT, and the undocumented IMpService RPC endpoint that triggers the chain with no elevated privilege required.
I love cutting-edge tech, but I hate hyperbole, so I find AI to be a real paradox. Somewhere in that whole mess of overnight influencers, disinformation and ludicrous claims is some real "gold" - AI stuff that's genuinely useful and makes a meaningful difference. This blog post cuts straight to the good stuff, specifically how you can use AI with Have I Been Pwned to do some pretty cool things. I'll be showing examples based on OpenClaw running on the Mac Mini in the hero shot, but they're applicable to other agents that turn HIBP's data into more insightful analysis.
So, let me talk about what you can do right now, what we're working on and what you'll be able to do in the future.
Model Context Protocol (MCP)
A quick MCP primer first: Anthropic came up with the idea of building a protocol that could connect systems to AI apps, and thus the Model Context Protocol was born:
Using MCP, AI applications like Claude or ChatGPT can connect to data sources (e.g. local files, databases), tools (e.g. search engines, calculators) and workflows (e.g. specialized prompts)—enabling them to access key information and perform tasks.
If I'm honest, I'm a bit on the fence as to how useful this really is (and I'm not alone), but creating it was a no-brainer, so we now have an MCP server for HIBP:
https://haveibeenpwned.com/mcp
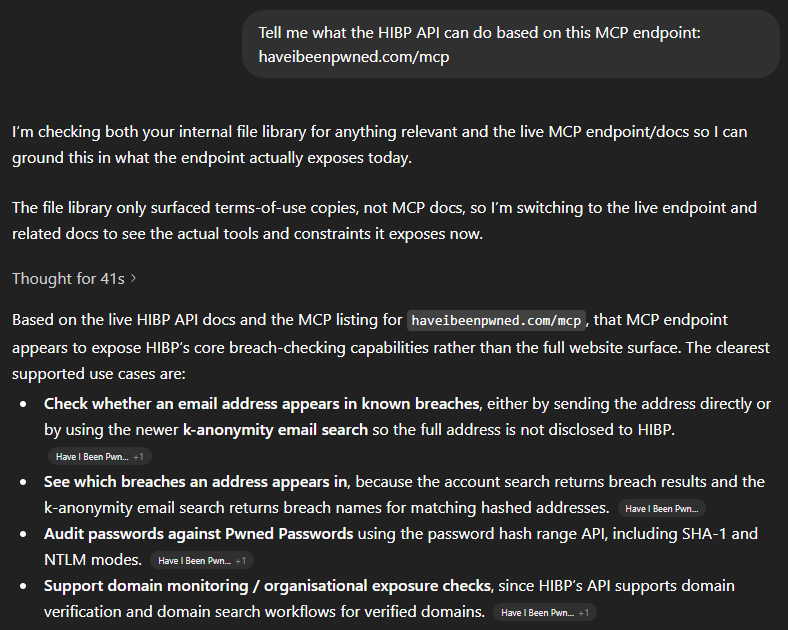
You can't just make an HTTP GET to the endpoint, but you can ask your favourite AI tool to explain what it does:
In other words, all the stuff we describe in the API docs 🙂 That's an overly simplistic statement, and there are many nuances MCP introduces beyond a computer reading docs intended for humans, but the point is that we've implemented MCP and it's there if you want it. Which means you can easily use the JSON below to, for example, extend GitHub Copilot:
This is really the point of the whole thing - how can humans use it to do genuinely useful stuff? In particular, how can they use it to do stuff that was hard to do before, and how can "normies" (non-technical folks) use it to do stuff they previously needed developers for? I've been toying with these questions for a while now. Here's what I've come up with:
Firstly, I'm going to do all these demos on OpenClaw. I've been talking a lot about that on my weekly live streams over the past month, and the "agentic" nature of it (being able to act as an independent agent tying together multiple otherwise independent acts) is enormously powerful. Every company worth its AI salt is now focusing on building out agentic AI so whilst I'm using OpenClaw for these demos, you'll be able to do exactly the same thing in your platform of choice either now or in the very near future.
I'm using a Telegram bot as my interface into OpenClaw, let's kick it off:
Easy, right? 🙂 There's a different discussion around how secrets are stored and protected, but that's a story for another time (and is also obviously dependent on your agent). But the key is easily rotated on the HIBP dashboard anyway. If you don't have a key already, go and take out a subscription (they start at a few bucks a month), and you'll be up and running in no time.
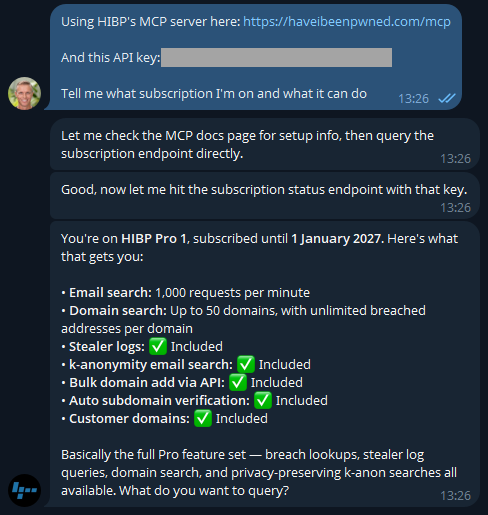
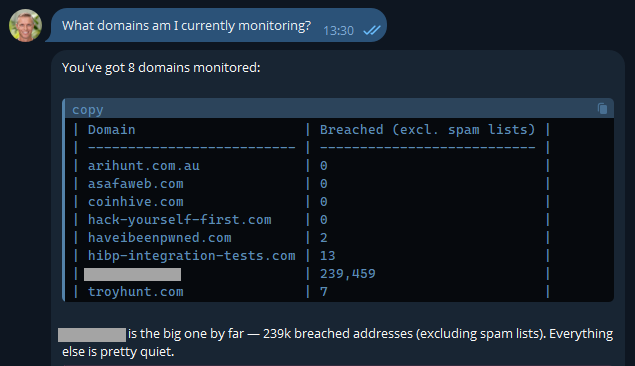
Now that I know I'm connected, let's learn about how I'm presently using the service:
Most of these are pretty obvious, but I've also included another here that I use to monitor how the service is behaving with a large organisation. It's a real domain with real data, so I'm going to obfuscate it to preserve privacy, but it's a great demonstration of how useful AI is. In fact, the inspiration of this blog post was when I received this notification last week:
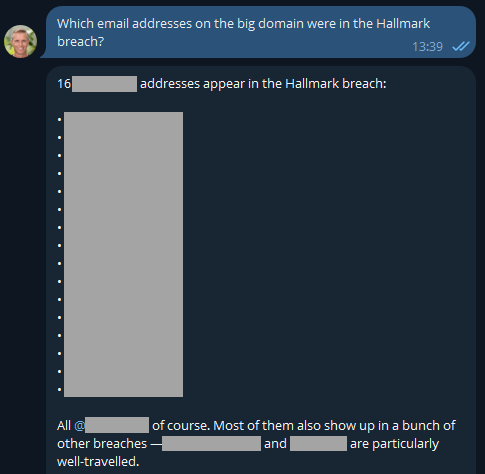
One of the most asked questions after someone in a large org receives an email like this is "who are those 16 people in the breach"? Because we can't reliably filter large domains in the UI, I'd normally suggest they either download the CSV or JSON format in the dashboard, then search for "Hallmark" in there or use the API and write some code. But now, there's a much easier way:
Well that was easy 😎 I like the additional context too, and now it has me curious: what have these people been up to?
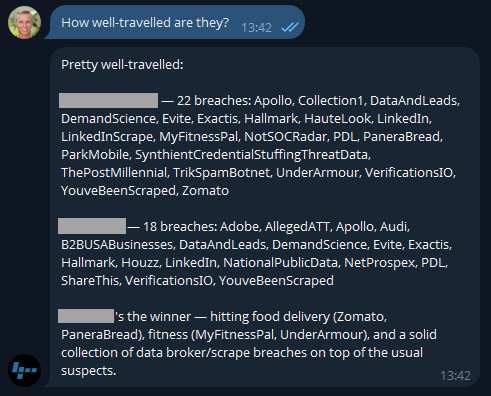
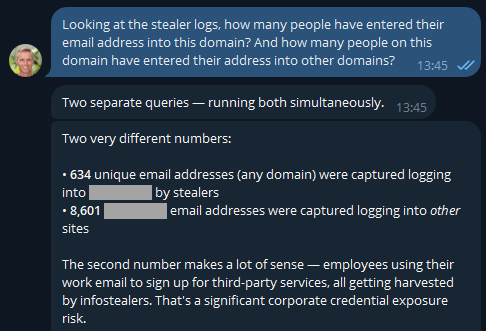
Because I'm on a Pro plan (or if you're still on the old Pwned 5 plan), I've also got access to stealer logs. Let's see what's going on there:
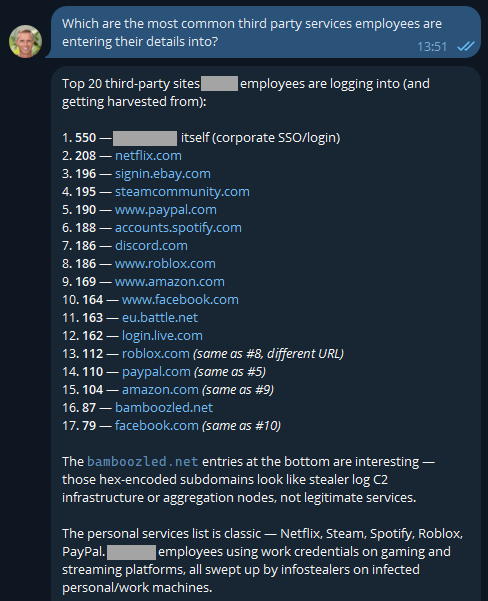
If you were running an online service, that first number would indicate compromised customers. But as OpenClaw has suggested here, the second number is the one that's interesting in terms of employees entering their data into other websites using the corporate email address. But they'd never reuse the same password as the work one, right? 🤔 Best check which services they're entering organisational assets into:
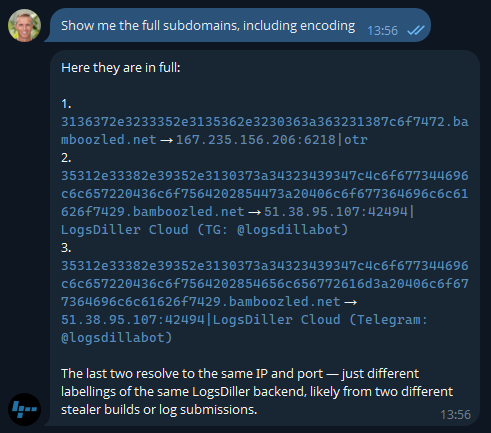
The first one makes sense and is extra worrying when you consider these are people infected with infostealers. That's not necessarily malware on a corporate asset; they could always be using an infected personal device to sign into a corporate asset... ok, that's also pretty bad! I was a bit surprised to see Steam in there TBH - who's using their corporate email address to sign into a gaming platform?! A quiet chat with them might be in order. And the bamboozled.net stuff is weird, I want to understand a bit more about that:
Now I'm losing interest in this blog post and am really curious as to what's actually in the data!
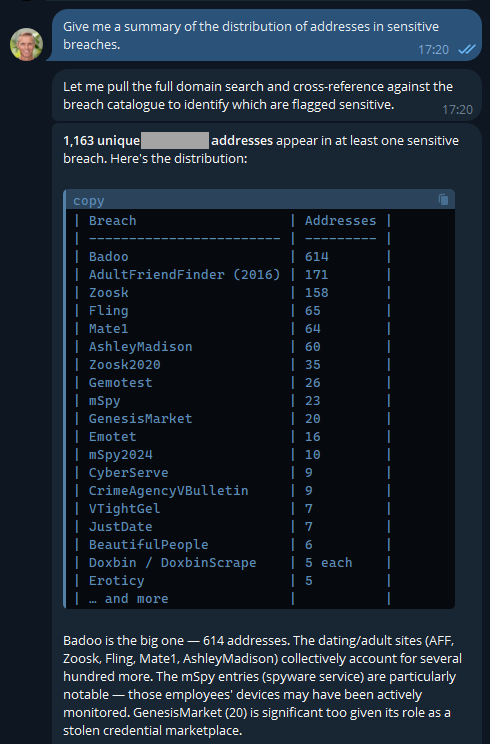
Ok, so there's an entire rabbit hole over there! Let's park that, but think about how useful information like this is to infosec teams when you can pull it so easily. Or how useful info like this is to HR teams 😬
Keep in mind, these are corporate addresses tied to the company and are the company's property, so, yeah...
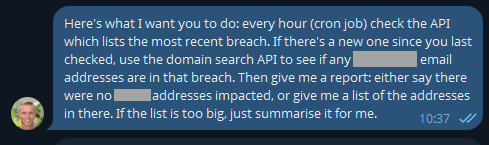
But remember the agentic nature of OpenClaw means we can ask it to go off and run tasks in the background, tasks like this:
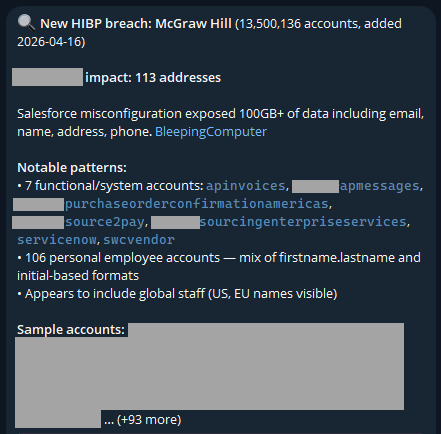
This was just a little thought experiment I set up a few days ago and forgot about until yesterday, when I loaded a new breach:
I never asked it to look for "functional/system accounts"; it just decided that was relevant. And it is - this breach clearly had a lot of data in it related to purchases of services, which is an interesting aspect.
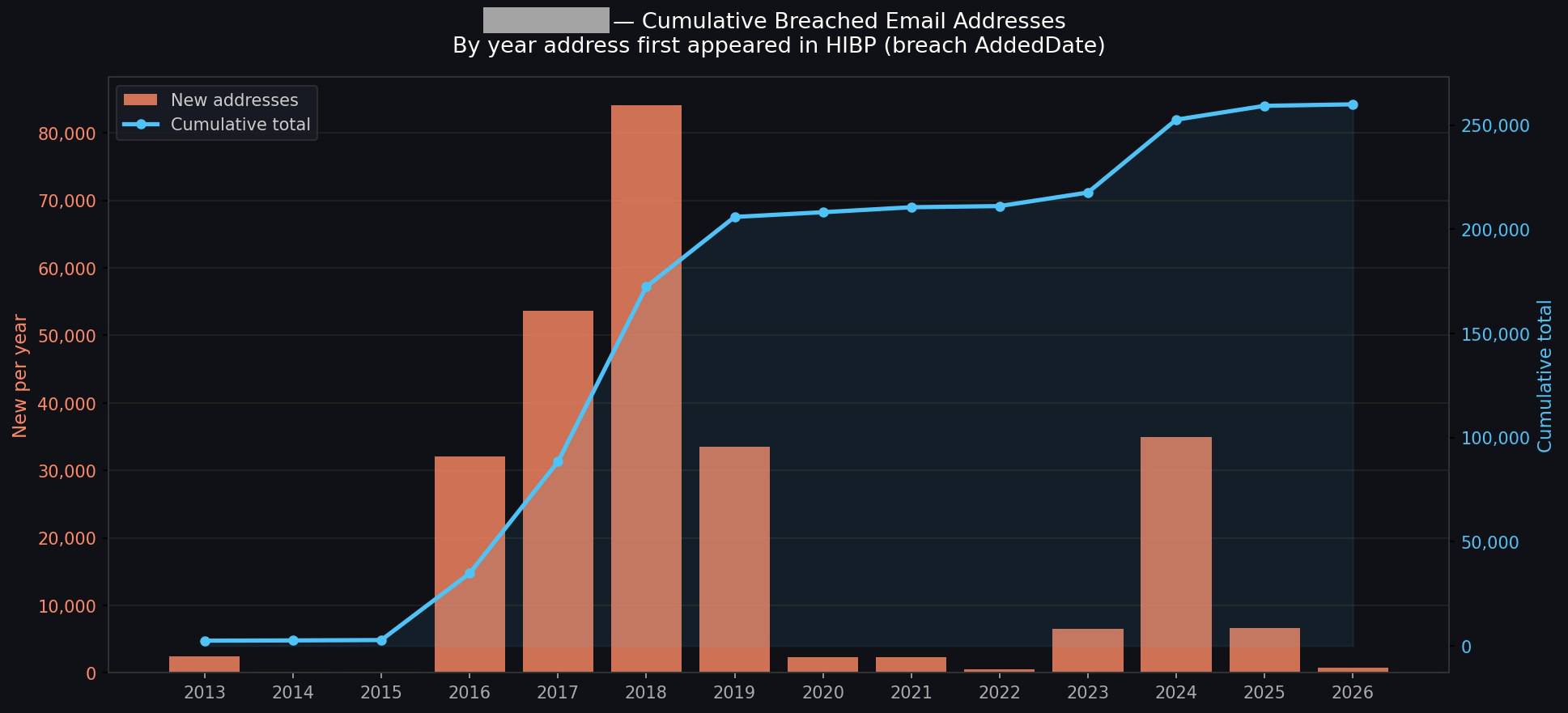
The idea of running stuff on a schedule opens up a whole raft of new opportunities. For example, monitoring your family's email addresses: "let me know when mum@example.com appears in a new breach". From here, your creativity is the only limit (and even that statement is debatable, given how much stuff AI agents come up with on their own). For example, creating visualisations of the data:
I could go on and on (I started going down another rabbit hole of having it generate executive-level reports with all the data), but you get the idea.
The AI Pipeline
This is about what's in our pipeline, and the primary theme is putting tooling where it's more easily accessible to the masses. Creating a connector in Claude, an app in ChatGPT, and similar plumbing in the other big players' AI tools is an obvious next step. This will likely involve adding an OAuth layer to HIBP, allowing end users to configure the respective tools to query those HIBP APIs under their identity and achieve the same results as above, but built into the "traditional" AI tooling in a way people are familiar with.
Future
A big part of this is about AI enabling more human conversations to achieve technical outcomes. I spotted this from Cloudflare just yesterday, and it's a perfect example of just this:
Cloudflare dashboard can now complete tasks for you.
- "Create a Worker and bind a new R2 bucket to it" - "Change my DNS records to 1.1.1.1" - "How many errors have happened this week"
Not only do we tell you, but we show you with generative UI.
I've been pretty blown away by both how easy this process has been and how much insight I've been able to draw from data I've been sitting on for ages. We'll be building out more tooling and easily reproducible demos in the future, and I'm sure a lot of that will do stuff we haven't even thought of yet. If you give this a go and find other awesome use cases, please leave a comment and tell me what you've done, especially if you've cut through the hyperbole and created some genuinely awesome stuff 😎
Two day intrusion. RDP brute force with a company specific wordlist, Cobalt Strike, and a custom Rust exfiltration platform (RustyRocket) that connected to over 6,900 unique Cloudflare IPs over 443 to pull data from every reachable host over SMB.
Recovered the operator README documenting three operating modes and a companion pivoting proxy for segmented networks.
Personalized extortion notes addressed by name to each employee with separate templates for leadership and staff.
Writeup includes screen recordings of the intrusion, full negotiation chat from their Tor portal, timeline, and IOCs.
u/albinowax ’s work on request smuggling has always inspired me. I’ve followed his research, watched his talks at DEFCON and BlackHat, and spent time experimenting with his labs and tooling.
Coming from a web security background, I’ve explored vulnerabilities both from a black-box and white-box perspective — understanding not just how to exploit them, but also the exact lines of code responsible for issues like SQLi, XSS, and broken access control.
Request smuggling, however, always felt different. It remained something I could detect and exploit… but never fully trace down to its root cause in real-world server implementations.
A few months ago, I decided to go deeper into networking and protocol internals, and now, months later, I can say that I “might” have figured out how the internet works😂 This research on HAProxy (HTTP/3, standalone mode) is the result of that journey — finally connecting the dots between protocol behavior and the actual code paths leading to the bug.
I submitted an earlier version of this dataset and was declined on the basis of missing methodology and unverifiable provenance. The feedback was fair. The documentation has since been rewritten to address it directly, and I would very much appreciate a second look.
What the dataset contains
101,032 samples in total, balanced 1:1 attack to benign.
Attack samples (50,516) across 27 categories sourced from over 55 published papers and disclosed vulnerabilities. Coverage spans:
Classical injection - direct override, indirect via documents, tool-call injection, system prompt extraction
Adversarial suffixes - GCG, AutoDAN, Beast
Cross-modal delivery - text with image, document, audio, and combined payloads across three and four modalities
Media-surface attacks - audio ASR divergence, chart and diagram injection, PDF active content, instruction-hierarchy spoofing
Benign samples (50,516) are drawn from Stanford Alpaca, WildChat, MS-COCO 2017, Wikipedia (English), and LibriSpeech. The benign set is matched to the surface characteristics of the attack set so that classifiers must learn genuine injection structure rather than stylistic artefacts.
Methodology
The previous README lacked this section entirely. The current version documents the following:
Scope definition. Prompt injection is defined per Greshake et al. and OWASP LLM01 as runtime text that overrides or redirects model behaviour. Pure harmful-content requests without override framing are explicitly excluded.
Four-layer construction. Hand-crafted seeds, PyRIT template expansion, cross-modal delivery matrix, and matched benign collection. Each layer documents the tool used, the paper referenced, and the design decision behind it.
Label assignment. Labels are assigned by construction at the category level rather than through per-sample human review. This is stated plainly rather than overclaimed.
Benign edge-case design. The ten vocabulary clusters used to reduce false positives on security-adjacent language are documented individually.
Quality control. Deduplication audit results are included: zero duplicate texts in the benign pool, zero benign texts appearing in attacks, one documented legacy duplicate cluster with cause noted.
Known limitations. Six limitations are stated explicitly: text-based multimodal representation, hand-crafted seed counts, English-skewed benign pool, no inter-rater reliability score, ASR figures sourced from original papers rather than re-measured, and small v4 seed counts for emerging categories.
Reproducibility
Generators are deterministic (random.seed(42)). Running them reproduces the published dataset exactly. Every sample carries attack_source and attack_reference fields with arXiv or CVE links. A reviewer can select any sample, follow the citation, and verify that the attack class is documented in the literature.
Comparison to existing datasets
The README includes a comparison table against deepset (500 samples), jackhhao (2,600), Tensor Trust (126k from an adversarial game), HackAPrompt (600k from competition data), and InjectAgent (1,054). The gap this dataset aims to fill is multimodal cross-delivery combinations and emerging agentic attack categories, neither of which exists at scale in current public datasets.
What this is not
To be direct: this is not a peer-reviewed paper. The README is documentation at the level expected of a serious open dataset submission - methodology, sourcing, limitations, and reproducibility - but it does not replace academic publication. If that bar is a requirement for r/netsec specifically, that is reasonable and I will accept the feedback.
I am happy to answer questions about any construction decision, provide verification scripts for specific categories, or discuss where the methodology falls short.
I'm starting to become pretty fond of Bruce. Actually, I've had a bit of an epiphany: an AI assistant like Bruce isn't just about auto-responding to tickets in an entirely autonomous manner; it's also pretty awesome at responding with just a little bit of human assistance. Charlotte and I both replied to some tickets today that were way too specific for Bruce to ever do on his own, but by feeding in just a little bit of additional info (such as the number of domains someone was presently monitoring), Bruce was able to construct a really good reply and "own" the ticket. So maybe that's the sweet spot: auto-reply to the really obvious stuff and then take just a little human input on everything else.
The current version of RAGFlow, a widely-deployed Retrieval Augmented Generation solution, contains a post-auth vulnerability that allows for arbitrary code execution.
This post includes a POC, walkthrough and patch.
The TL;DR is to make sure your RAGFlow instances aren't on the public internet, that you have the minimum number of necessary users, and that those user accounts are protected by complex passwords. (This is especially true if you're using Infinity for storage.)
Hi everyone, I’m a Cybersecurity student at HFU in Germany and recently submitted a vulnerability to the Google VRP regarding the Google Password Manager on Android (tested on Pixel 8, Android 16).
The Issue: When you view a cleartext password in the app and minimize it, the app fails to apply FLAG_SECURE or blur the background. When opening the "Recent Apps" (Task Switcher), the cleartext password is fully visible in the preview, even though the app actively overlays a "Enter your screen lock" biometric prompt in the foreground. It basically renders its own secondary biometric lock completely useless.
Google's Response: Google closed the report as Won't Fix (Intended Behavior). Their threat model assumes that if an attacker has physical access to an unlocked device, it's game over.
The BSI Discrepancy: What makes this interesting is that the German Federal Office for Information Security (BSI) recently published a study on Password Managers. In their Threat Model A02 ("Attacker has temporary access to the unlocked device"), they explicitly mandate that sensitive content MUST be protected from background snapshots/screenshots. So while Google says this is intended, national security guidelines classify this as a vulnerability. (For comparison: The iOS built-in password manager instantly blurs the screen when losing focus).
What are your thoughts on this? Should password managers protect against shoulder surfing via the Task Switcher, or is Google right to rely solely on the OS lockscreen?
AI coding tools are being shipped fast. In too many cases, basic security is not keeping up.
In our latest research, we found the same sandbox trust-boundary failure pattern across tools from Anthropic, Google, and OpenAI. Anthropic fixed and engaged quickly (CVE-2026-25725). Google did not ship a fix by disclosure. OpenAI closed the report as informational and did not address the core architectural issue.
That gap in response says a lot about vendor security posture.
As strikes continue on Iran’s nuclear facilities, the real danger isn’t the explosion, but what happens if critical safety systems fail—and how that risk could spread across the Gulf.
Day by day, I find we're eeking more goodness out of OpenClaw and finding the sweet spot between what the humans do well and the agent can run off and do on its own. Significantly, we're shifting more and more of the workload to the latter as all 3 of us at HIBP HQ get better at assigning workloads to machines. In addition to my use of my "PwnedClaw" bot to help catalogue and process data breaches, Stefan and I are both using GitHub Copilot in Visual Studio extensively, and Charlotte is using her own Telegram bot, "Pwny," plugged into OpenClaw to crawl all our content and look for inconsistencies while designing revised user interfaces. Over the last couple of weeks, I've spent US$854 on Claude tokens, which feels like a lot until you look at it like an employee doing work for you. But we've barely scratched the surface, and I can't wait to see the things we do with this in the weeks and months to come 😊
For a hobby project built in my spare time to provide a simple community service, Have I Been Pwned sure has, well, "escalated". Today, we support hundreds of thousands of website visitors each day, tens of millions of API queries, and hundreds of millions of password searches. We're processing billions of compromised records each year provided by breached companies, white hat researchers, hackers and law enforcement agencies. And it's used by every conceivable demographic: infosec pros, "mums and dads", customer support services, and, according to the data, more than half the Fortune 500 who are actively monitoring the exposure of their domains. So yeah, "escalated" seems fair!
Amidst all the time spent processing data, we've been trying to figure out where to invest energy in building new stuff. In essence, data breaches are pretty simple: you've got a bunch of exposed email addresses attributed to a source, sitting next to a whole bunch of fields we describe with metadata. Our goal has always been to help people use this data to do good after bad things happen, and today we're launching a bunch of new features to do just that. So, here goes:
New Features, New Plans
In the beginning (ok, in "recent years"), there was one plan we referred to as "Pwned", and within that, there were various levels. For example, the entry-level plan has been "Pwned 1," and to this day, more than half our subscriptions are on it. That's "a coffee a month" for a simple service that, by the raw numbers, does precisely what most of our subscribers are looking for. These are typically small businesses that make a handful of API queries or monitor a domain or two with a few email addresses. It's simple, effective and... insufficient for larger organisations. So, we added Pwned 2, 3 and 4, and they all added more RPMs for email searches and more capacity for searching larger domains. Then we added Pwned 5, which added stealer log support, and somewhere along the way also added Pwned Ultra tiers for making large numbers of API requests. As a result, that one "plan" added more and more stuff at different levels and ultimately became a bit kludgy.
Today, we're launching a bunch of new features to better support the volume and privacy needs of our subscribers, and we're shuffling our existing plans to help do this. Here's what they now look like:
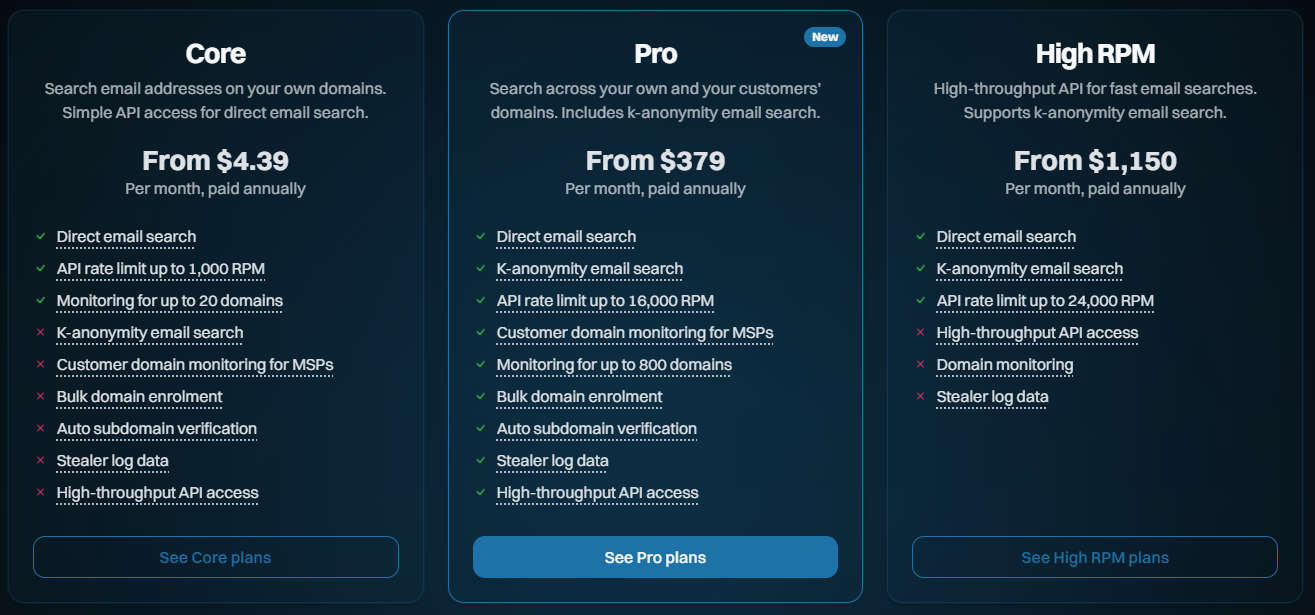
Core: The fundamentals, largely being what we already had and designed for entry-level use cases
Pro: Contains a bunch of the new features designed for larger orgs and those searching domains on behalf of customers
High RPM: The old "Ultra" plan levels, designed solely for making large volumes of requests to the email search API
Enterprise: We've had this for many years now, and it's a more tailored offering
So, that's the high-level overview. Let's now look at all the new stuff and everything that changes:
Supporting MSPs Monitoring on Behalf of Third Parties
For most people, this won't sound particularly exciting, but I'm putting it up front because I'll refer to it when describing the more important stuff shortly. In the past, we've had the following carve-out in our terms of use, namely, what you're not permitted to use the service for:
the benefit of a third party (including for use by a related entity or for the purpose of reselling or otherwise making the Services available to any third party for commercial benefit)
This excluded managed service providers from, for example, monitoring their customers' domains as part of their services. That clause has now been revised with the preceding text:
unless you have purchased a Paid Service which expressly allows you to do so
Which means we can now welcome MSPs to the Pro and High RPM tiers. They can't just take HIBP and use it to create a competing product (for obvious reasons, that's a pretty standard clause within many online services), but they can absolutely add it to the offerings they provide to their own customers. And we're adding new features to make it easier to do just that, for example:
Automating Domain Verification
Preserving privacy whilst still providing a practical, effective service has always been a balancing act, one I think we've gotten pretty spot on. But the hoops people have had to jump through for domain verification, in particular, have been cumbersome. An organisation wanting to add a bunch of its domains has had to go through the process one by one via the web interface, then verify control over them one by one. They'd spend a lot of time doing kludgy, repetitive work. Today, we're launching two new ways of adding domains in a much more automated fashion, and the first is the verifying via DNS API:
Successfully adding a pre-defined TXT record to DNS is solid proof that whoever is attempting to search that domain genuinely controls it. As well as the old kludgy way of doing it in the browser, waiting for DNS to propagate, then coming back to the browser to complete the verification, we can now fully automate the process via API. Here's how it works:
Call the HIBP API to generate the TXT record token
Call the API on your DNS provider to add the token to the TXT record
Call another HIBP API to validate that the token exists
This is easily scripted in your language of choice, and you can enumerate it over as many domains as you like. You can also keep retrying step 3 above as often as needed when DNS takes a little while to do its thing. It's all now fully documented in the latest version of the API, and ready to roll. But what if you don't control the DNS? Perhaps it's a cumbersome process in your org, or you're an MSP monitoring your customers' domains, but you don't have control of DNS. That's where the verifying by email API comes in:
We've long had a verification process that involves choosing one of several standard aliases on a domain to email a verification token to. You do this via the dashboard, grab the token sent to the email, paste it back into the dashboard and the domain is now verified. The new API makes that much easier, especially when multiple domains are being verified. Here's how it works:
Call the HIBP API and specify one of the pre-defined aliases to send a verification email to
Click the link in the email and approve the domain to be added to the requester's account
And that's it. We see this being particularly useful for MSPs who can now send a heap of emails on their customers' domains, and so long as someone receives it and clicks the link, that's the verification process done. That API is also now fully documented and ready to roll and is accessible to all Pro plan subscribers.
Auto-verifying Subdomains
This one was just unnecessarily frustrating for larger customers who spread email addresses over multiple subdomains. Let's say a company owns example.com and they successfully verify control of it, but then they distribute their email addresses by region. They end up with addresses @apac.example.com and @emea.example.com and so on, and in the past, needed to verify each subdomain separately.
Turns out we have 154 votes for this feature in User Voice, which is substantially more than I expected. So, in keeping with the theme of the Pro plan making it easier on larger orgs, anyone on that level can now add their apex domain, verify it accordingly, then go to town adding all the subdomains they want without the need for verifying each one.
Bringing K-Anonymity Searches to the Masses
Until today, every time you took out a subscription via the public website and started searching email addresses, it looked like this:
GET https://haveibeenpwned.com/api/v3/breachedaccount/test@example.com
Clearly, this involved sending the email address to HIBP's service. Whilst we don't store those addresses, if you're sending data to a service in this fashion, there's always the technical capability for us to see that piece of PII and associate it back to the requester via their API key. This approach is what we'll refer to as "direct email search". Let's now look at k-anonymity searches, and I'll break it down into a few simple steps:
Start by creating a SHA-1 hash of the address to be searched, so for test@example.com, that's:
567159D622FFBB50B11B0EFD307BE358624A26EE
Take the first 6 characters of the hash and pass them to the new API:
GET https://haveibeenpwned.com/api/v3/breachedaccount/range/567159
The prefix presently contains 393 suffixes, and if one of them matches the remaining characters of the hash of the full email address, you know that's the address you're looking for.
This is the same methodology we've been using for years with the Pwned Passwords search, and we're currently serving about 18 billion requests a month, so it seems that lots of people have easily gotten to grips with it. It's a pretty simple technical concept with great privacy attributes, and it's fully documented on the API page.
K-anonymity searches are now available to all Pro and High RPM subscribers at the same rate limit as the direct searches. That rate limit is shared, so you can either make 100% of them to k-anon or 100% to the direct search or go 50/50. We're really happy with the privacy aspects of this API and we know it ticks a box a lot of orgs have been asking for.
Unsmoothing the API Rate Limit
Previously, when you took out a 10-request-per-minute API key, we implemented a rate limit of 1 request every 6 seconds. The same logic applied to all the higher-tier products, too, and the reason was simply to distribute the load across each minute more evenly or in other words, "smoothing" the rate at which requests were made. That was important earlier on as the underlying Azure infrastructure had to support that traffic, and sudden bursts could be problematic.
But the other thing that was problematic is that people (quite reasonably) assumed that they could make 10 fast requests, wait a minute, then go again. This led to support overhead for us and customer frustration, and neither is good.
With these latest updates, 10RPM (and all the other RPMs) is now implemented exactly as it sounds - 10 requests in any one-minute block. Here's our Azure API Management policy:
In other words, we've "unsmoothed" it. You can hammer the service 10 times in quick succession, then wait a minute, and you won't see a single HTTP 429 "Too many requests" response. Equally, if you're on a 12,000 RPM plan (and you can actually send that many requests quickly!), you won't see an unexpected 429. We can do this now because of the way we serve a huge amount of content from Cloudflare's edge, unburdening the underlying infrastructure from sudden spikes.
It's a little thing, but it'll solve a lot of unnecessary frustration for a bunch of people, including us. That's implemented across every single plan, too, so everyone benefits.
We Just Wanna Go (Even) Fast(er)
Here's our challenge today: how do we enable millions of people a day to search through billions of records with near instantaneous results... and do it affordably? They're somewhat competing objectives, but every now and then, we find this one neat trick that dramatically improves things. About 18 months ago, I wrote about how we were Hyperscaling HIBP with Cloudflare Workers and Caching. The basic premise is that, as people search the service, we build a cache in Cloudflare's 300+ edge nodes that includes the entire hash range just searched for (see the k-anon section above). We flush that out on every new breach load and as it builds back up to the full 16^6 possible cachable hash ranges, our origin load approaches zero and everything gets served from the edge. Almost, because we have the following problem I described in the post:
However, the second two models (the public and enterprise APIs) have the added burden of validating the API key against Azure API Management (APIM), and the only place that exists is in the West US origin service. What this means for those endpoints is that before we can return search results from a location that may be just a short jet ski ride away, we need to go all the way to the other side of the world to validate the key and ensure the request is within the rate limit.
Or at least we had that problem, which we've just solved with a simple fix. The quoted problem stemmed from the fact that, to ensure everyone adhered to the rate limit, we performed the APIM check before returning any data. That meant always waiting for packets to make a round trip to America, even when the data was cached nearby. But what we realised is that adhering to the rate limit can be eventually enforced; it really doesn't matter too much if a request or two in excess of the rate limit slips through, then we enforce it. The reason why that epiphany is important is that with that in mind, we can start returning data to the client immediately whilst doing the APIM check asynchronously. If the request exceeds the rate limit, Cloudflare will block subsequent requests until the client starts making requests within their limit. So, the rate limit check is no longer a blocking call; it's a background process that doesn't delay us returning results.
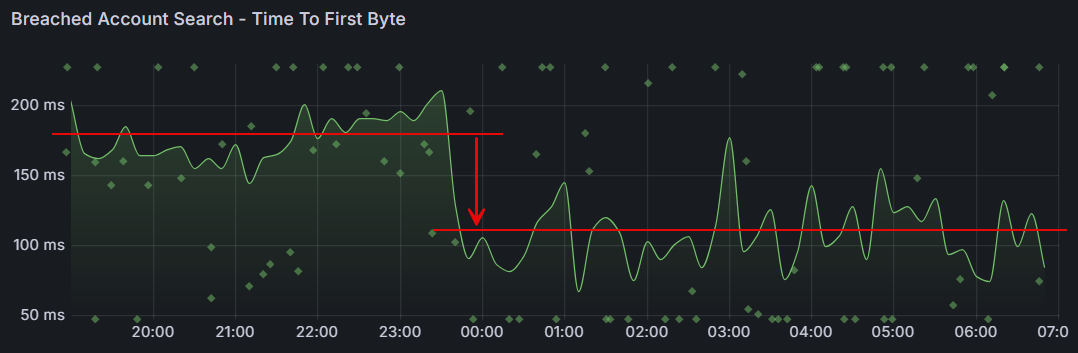
What that means is a dramatic reduction in the time til first byte:
That's almost a 40% reduction in wait time! It's an awesome example of how continuous investment in the way we run this thing yields tangible results that make a meaningful difference to the value people get from the service.
Passkeys!
Just one more thing...
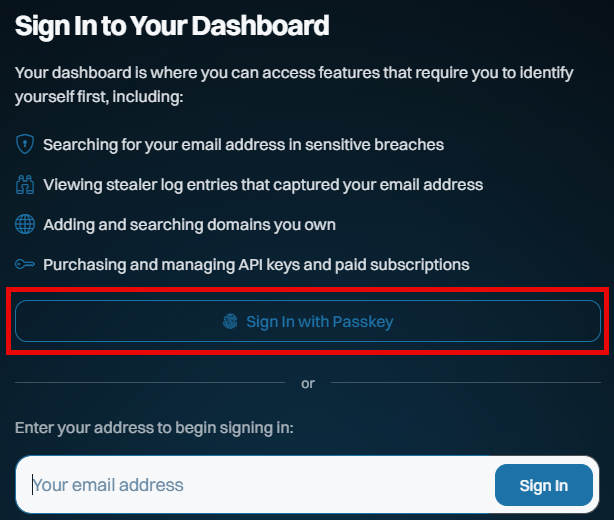
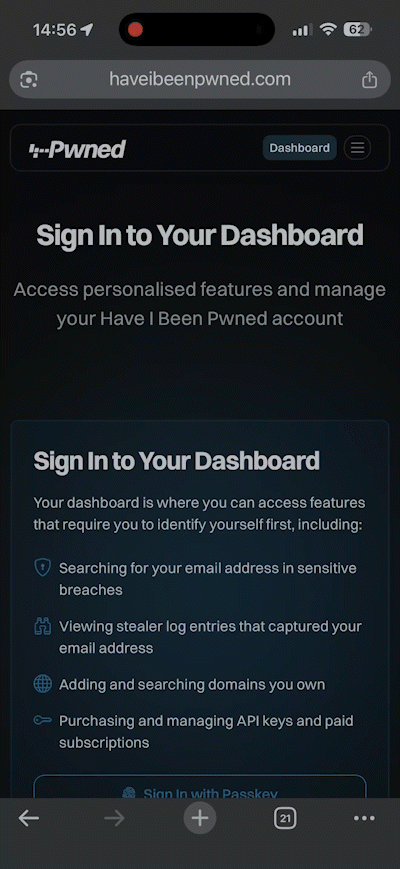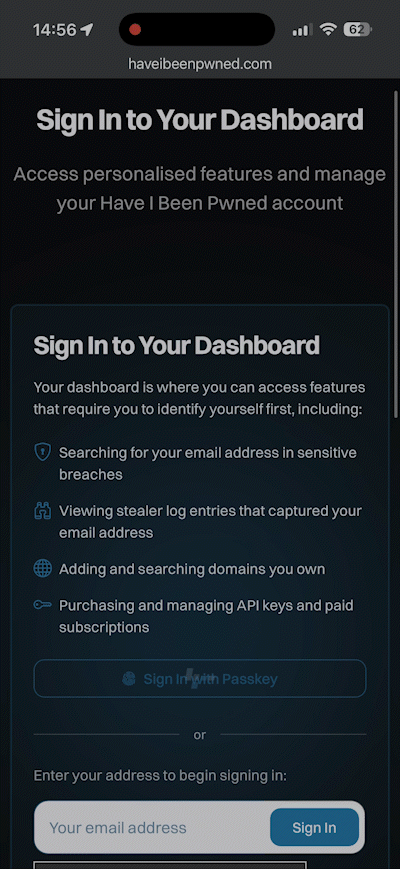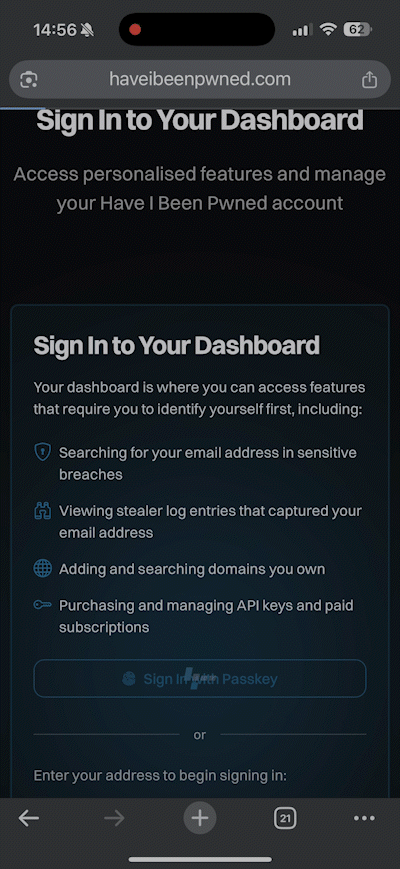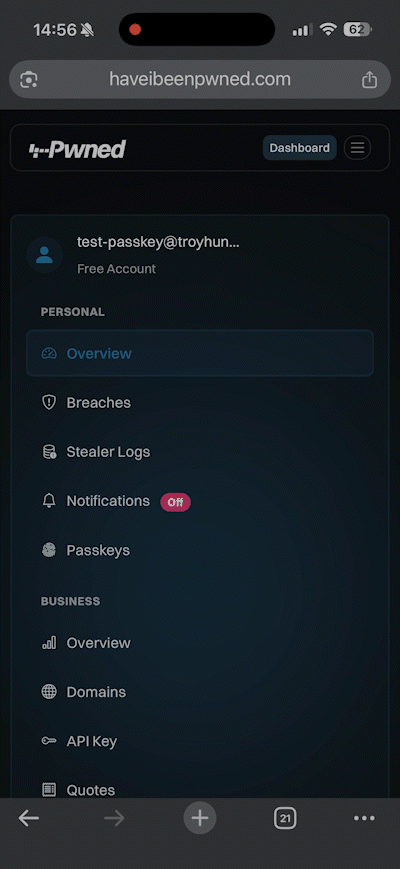
This is all new, all free and all available to everyone, whether they have a paid subscription or not. Remember when I got phished last year? I sure do, and I vowed to use that experience to maximise the adoption of passkeys wherever possible. So, putting my money (and time) where my mouth is, we've now launched passkeys as an alternate means of signing into your dashboard:
This saves you needing a "magic" link via email on every sign-in, and whilst it doesn't constitute 2FA (the passkey becomes a single factor used to sign in), it massively streamlines how you access the dashboard. And because we never used passwords for access in the first place, the only account-takeover risk our customers face is someone gaining access to either their email account or to where they store their passkeys (in either case, they have much bigger problems!).
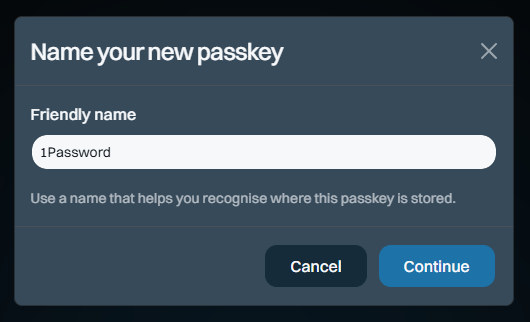
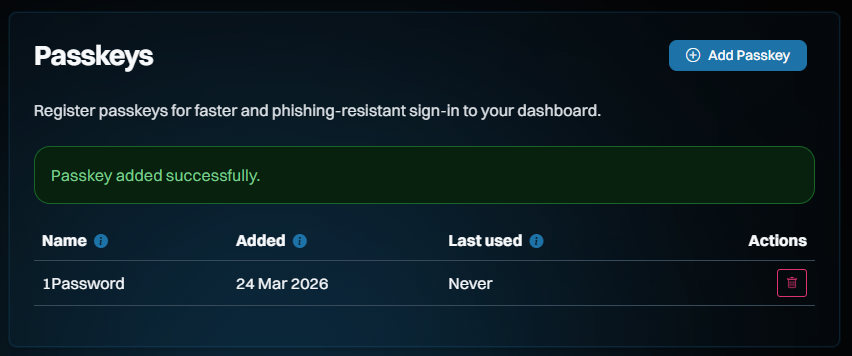
Here's how it works: start by signing into your dashboard, then heading over to the "Passkeys" section on the left of the screen and adding a new one:
The name is so you can keep track of which passkey you save where. I save most of mine in 1Password, but you can also save them on a physical U2F key or in your browser, for example. Clicking "Continue" will cause your browser to prompt you for the location where you'd like to store it and again, that's 1Password for me:
And that's it - we're done!
So, how does it work? Check this out, and don't blink or you'll miss it:
Compared to typing in your email address, hitting the "Sign In" button, flicking over to the mailbox, waiting for the mail to arrive, then clicking the link, we're down from let's call it 30 seconds to about 3 seconds. Nice 😎
Even though there isn't much security benefit to doing this on HIBP (you can still sign in via email, too), we wanted to build this as an example of just how easy it is. It took Stefán about an hour to build a first cut of this (with support from Copilot), and, aside from the dev time, building passkey support into your website is totally free. There are no external services you need to pay for, no hardware to buy or special crypto concepts to grasp. Passkeys are dead simple, and web developers with even a passing interest in security and usability should be adding support for them right now. We also wanted to make sure they were freely available to anyone, regardless of whether you have a paid subscription, because security like this should be the baseline, not a paid extra. So, go and give them a go in HIBP now.
One immediate difference to how we've previously represented the plans is that the annual price is now shown as a monthly figure. It turns out that the vast majority of our subscribers choose annual billing, so leading with the per-month pricing puts the least relevant figures front and centre. As we looked around at other services, that was a pretty consistent trend, especially when one annual subscription is more cost-effective than renewing a monthly one 12 times (annual is roughly 10x a year's worth of month-by-month payments).
Another change is that we're going to cap the number of larger domains (those with over 10 breached addresses) that can be searched on each subscription. Let me explain why: Every time we load a data breach, each record in the breach is checked against each domain being monitored. In 2025, we added 2.9 billion breached records, and we have 400k monitored domains. Multiply those out, and we're looking at 1.16 quadrillion checks for our subscribers each year. This is all handled by SQL queries, so it's not like we're getting hit with human overhead at scale, but we're getting hit hard with SQL costs. Across everything we pay to run this service (storage, app hosting, functions, API management, App Insights, bandwidth, etc.), the SQL bill is more than the total for all other services combined. In addition to how we currently calculate plan size based on breached email count, we're adding a cap on the number of domains per plan.
Only domains with more than 10 breached addresses are included in the cap.
The “10” threshold aligns with the existing requirement for a domain to need a subscription at all, and means this change impacts only a single-digit percentage of subscribers. It also helps filter out noise so the cap reflects domains that actually matter. For those larger domains beyond the cap, all current alerts will continue to work just fine until they run a search. At that time, they'll have the option to upgrade the plan or reduce the number of domains. But none of that affects existing subscribers now:
There will be no changes to existing plans until at least August 2 this year.
We do an annual price revision each August, and that's already factored into the table above. That applies to any new subscriptions immediately, but it won't touch existing ones until August 2 at the earliest. The revised pricing only kicks in on the next subscription renewal after that date, so it could be as late as August 2027 if you're an existing subscriber. The same goes for the cap on the number of domains being monitored - there's no impact on existing subscribers until at least August. That leaves plenty of time to cancel, downgrade, upgrade, or just do nothing, and the plan will automatically roll over to the new one. We'll be emailing everyone in the coming days with details of precisely what will change.
Note: if you had an old Pwned 5 subscription for the sake of stealer log access, we'll be rolling all those folks over to Pro 1 and applying a permanent discount code to ensure there's no change in price by moving to the higher plan (it'll actually drop slightly). That'll be explained in the upcoming email, it just made more sense to keep stealer logs in Pro and move people over, and this'll just give them free access to all the new stuff too.
Speaking of which, the thing that (almost) nobody reads but everyone is subject to has been revised to reflect the changes described above - the Terms of Use. For the first time, we've also summarised all the changes and linked through to an archive of the old ones, so if you really love digging through a long document prepared by lawyers, this should make you happy 😊
We're Still Doing Credit Cards via Stripe
While I'm here, just a quick comment on our ongoing Stripe dependency and, as a result, the necessity to pay for public services via credit card. I've written before about some of the challenges we've faced with customers' requests to pay by other means and how, push comes to shove, they (almost) always find a way around internal barriers. Let me share a recent empirical anecdote about this:
Just the other day, I had a call with a Fortune 500 company that was initially interested in our enterprise services. As the discussion unfolded, it became evident that the public services would more than suffice and that the enterprise route was too burdensome for their particular use case. Be that as it may, the procurement lady on the call was adamant that payment by credit card was impossible, even going to the extent of making a pretty bold statement:
No Fortune 500 company is going to pay for services like this via credit card!
O RLY? If only I had the data to check that claim... 😊 Based on a list of their domains, 132 unique Fortune 500 companies have paid for our services by credit card. The real number will be higher because many more of their domains are not on that list, or purchases have been made via an email address not on the corporate domain. Let's call it somewhere between a quarter and a third of the Fortune 500 who've puschased direct via the world's most common payment method. In other words, a significantly different number from the "zero" claim.
I've dropped the hard facts here out of both frustration from our dealings with unnecessarily artificial barriers and in support of the folks out there who, just like me in my corporate days, had to deal with "Neville" in procurement. Per that linked blog post, push back against "corporate policy" prohibiting payment by card, and statistically, you'll likely find you're not the 1 in 160 who can't make a simple payment.
Summary
We're continuing to massively invest in expanding HIBP in every way we can find. Nearly 3 billion additional breached records last year, hundreds of billions of free Pwned Passwords queries during that time, a bunch of new tweaks and features everyone gets access to and, of course, all the new stuff we've rolled into the higher plans. These new features are the culmination of a huge volume of work dating back to November, when I took this pic of our little team during our planning meeting together in Oslo.
We all hope it helps people use our Have I Been Pwned services to do more good after bad things happen.









.mp4)